
「RAG(Retrieval Augmented Generation)なしで、PDFナレッジベースの検索・回答は実現できるのか?」
お客様からいただいたこの問いをきっかけに、Salesforce Agentforce と Multimodal AI を組み合わせた検証を実施しました。本ブログでは、その検証結果と実装アプローチを共有します。
Salesforce の Intelligent Context やデータライブラリ機能は、ドキュメントをインデックス化し、セマンティック検索で関連コンテンツを取得する仕組みです。一方で、以下のような課題が挙げられることがあります。
検証の問い:「RAGなしで、同等以上の品質を実現できるか?」
この問いに対して、Multimodal AI(Gemini 2.5 Pro)によるPDF解析と、カスタムオブジェクト+タグベース検索の組み合わせで検証を進めました。
複雑な表、チャート、グラフが含まれるPDFは、従来のテキスト抽出やOCRだけでは構造や数値の関係性を正確に保持しづらい場合があります。
Gemini 2.5 Pro の Multimodal 能力を活用し、PDFを「見て」理解し、以下のように構造化しました。
<table> に変換<h1>〜<h6>, <p>, <section>)で階層化これにより、Intelligent Context やデータライブラリに頼らず、PDFの構造と数値を保持した形でナレッジを蓄積できることを確認しました。
[PDFファイル]
↓ 非同期バッチ(PDFExtractBatch / PDFExtractScheduler)で処理
↓ Multimodal (Gemini 2.5 Pro) で抽出・構造化
[PDFExtract Prompt Template]
↓ チャンク分割・タグ自動生成
[PDF_Knowledge__c] カスタムオブジェクト
- Chunk1〜10(HTML形式)
- Tag(検索用タグ)
- FileName, FilePath(出典情報)
↓
[PDFTag__c] 全タグのマスタ
↓
[ユーザー質問] → Agentforce Topic Instruction
↓ 適切なアクションを呼び出し
[Evaluate_PDF_Tags] 質問とタグの関連性をLLMで評価
↓ 関連タグを特定
[PDF_Knowledge__c 検索] タグでLIKE検索
↓ 該当チャンク取得
[Search_PDF_Knowledge] 出典付き回答生成
↓
[HTML形式の回答]
PDF_Knowledge__c、PDFTag__c複雑な図表を含むPDFでも、数値や構造を保持した形で抽出できることを確認しました。
RAGではベクトル検索で「意味的に近い」ドキュメントを取得します。本検証では、代わりに以下を採用しました。
Evaluate_PDF_Tags Prompt Template で、ユーザー質問と全タグの関係性をLLMに評価PDF_Knowledge__c をLIKE検索し、該当チャンクを取得ドメインに応じた専門家視点をプロンプトに組み込むことで、タグ評価の安定性を高めています。
Search PDF Knowledge アクションを定義SearchPDFKnowledge がタグ評価→検索→回答生成をオーケストレーション本検証では、製造業の製品マニュアル・安全基準を想定したシナリオで動作確認を行いました。

"製品仕様","取扱説明","安全基準","保護具","手順","品質管理", "検査基準","許容値","チェックリスト","記録様式","図解","フローチャート"

1. ユーザーが Agent に質問 → 「安全作業の手順を教えて」 2. Topic Instruction が質問を解釈 → Search PDF Knowledge アクションを呼び出し 3. Evaluate_PDF_Tags でタグ評価 → 入力: Search_Term="安全作業の手順を教えて", All_Tags_Str="製品仕様","安全基準",... → 出力: relatedTags=["安全基準","手順","チェックリスト"] 4. PDF_Knowledge__c をタグで検索 → TagSearch__c LIKE '%安全基準%' OR LIKE '%手順%' OR LIKE '%チェックリスト%' 5. 該当チャンクを取得 → 安全基準ガイドライン.pdf の該当セクション 6. Search_PDF_Knowledge で回答生成 → 「安全作業の手順は以下の通りです。①保護具の着用確認 ②...」 → 出典:安全基準ガイドライン.pdf
各プロンプトの役割と、製造業シナリオに合わせた記述例を示します。
役割: PDFをMultimodalで解析し、HTML構造化・チャンク分割・タグ生成を行う。
主な指示(抜粋):
- 表 → HTML <table> に変換 - チャート・グラフ → データポイントをHTMLテーブルとして格納 - セクションは <section> または <div class='section'> でラップ - タグは3〜15個、ドキュメント内容から生成(例: "製品仕様","安全基準","許容値") - 出力はJSON形式(chunks, tags)、文字列内の " は \" でエスケープ
役割: ユーザー質問と全タグの関係性を評価し、関連タグを特定する。
入力: `Search_Term`, `All_Tags_Str`
主な指示(抜粋):
ROLE: ドキュメントの専門家として、質問に必要なナレッジにつながるタグを漏れなく拾う。 EVALUATION: - 直接一致: 質問のキーワードがタグに含まれる - 部分一致: タグが複合語で概念を含む - 意味的関連: 同じドメインを扱うタグ - 手段・方法: 質問が「方法」なら手順・チェックリスト関連のタグを含める DOMAIN HINTS(製造・品質管理の例): - 仕様・許容値 → 製品仕様、許容値、取扱説明、検査基準 - 手順・方法 → 安全基準、手順、チェックリスト、記録様式 - 保護・安全 → 保護具、安全基準
出力例:
{"relatedTags": ["安全基準", "手順", "チェックリスト"]}
役割: 検索で取得したナレッジを参照し、出典付きで回答を生成する。
入力: `Search_Term`, `Search_Results`(knowledge + sources のJSON)
主な指示(抜粋):
- 検索結果の knowledge のみを参照、捏造禁止 - 出典は必ず明示(例:出典:社内マニュアル / 安全基準ガイドライン.pdf) - 回答はHTML形式、簡潔に




結論: 社内マニュアル、製品ドキュメント、規程類など対象範囲が限定されている場合は、RAGなしで十分実用的です。横断的・大規模なナレッジ検索が必要になった段階で、RAGやハイブリッド検索への移行を検討するのが現実的です。
本検証で使用した Gemini 2.5 Pro は、RAG(検索で取得した断片を注入)とは異なり、ファイルコンテンツをそのままプロンプトに注入できる大きなコンテキストウィンドウを持ちます。
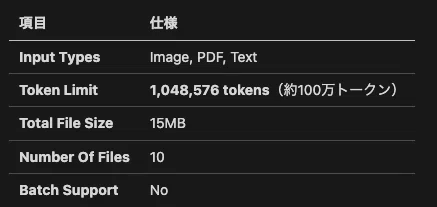
トークン数と文字数の換算は、言語や表記によって異なります。日本語の場合、一般的に 1 token ≈ 2〜3 文字 とされます(漢字・かな混じり文)。
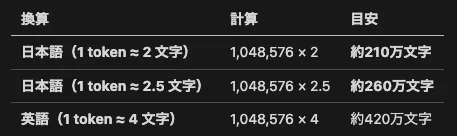
※ 出力トークン分を除くと入力に使えるのは約98万トークン程度。上記は理論上の最大値に近い目安です。
実務上の目安として、日本語の PDF・テキストであれば、おおよそ 150万〜200万文字 を 1 回のプロンプト呼び出しでコンテキストとして渡せます。一般的なビジネス文書(1ページ≈500〜800文字)に換算すると、約2,000〜4,000ページ分 に相当します。

ポイントは、ナレッジ量が100万文字程度に収まる場合、RAGで「検索→断片取得」するよりも、該当コンテンツをプロンプトに直接注入する Full Context 方式 の方が、情報の欠落が少なく、シンプルに実現できることです。本検証では、PDF をチャンク化してカスタムオブジェクトに格納し、タグで絞り込んだ上で該当チャンクをプロンプトに渡すハイブリッド方式を採用しています。
「RAGなしで実現できるか?」という問いに対して、Multimodal PDF解析 + カスタムオブジェクト + タグベース検索 の組み合わせで、同等以上の品質を実現できることを検証しました。
複雑な表・チャート・グラフを含むPDFを扱う場合、Multimodal AI による構造化が有効であり、RAGに頼らないシンプルなアーキテクチャでも、実用的なナレッジ検索・回答が可能であることを確認できました。
本ブログは検証結果の共有を目的としており、本番環境への適用にあたっては、ご利用環境に応じた評価・調整をお勧めします。




